Intro
Shape matching, stereo reconstruction, motion estimation, image restoration, and object segmentation are all problems in the field of Computer Vision that are often solved using global optimization methods. In this post, we will present typical nonlinear optimization challenges and suggest a graceful solution.
The calculus/optimization lovers will find themselves enjoying this one.
Challenges in Global Optimization
Initial Guess
Iterative methods require an initial starting point, also called: initial guess.
More so, optimization methods actually often require not just any initial guess but a “good” one; i.e., initial guess that falls inside the feasible region.
Such initial guess is not always an easy task.
Conditioning and Numerical Stability
Numerical stability is an important notion and must be maintained when applying numerical methods. If the problem (or objective function) is ill-conditioned then the numerical algorithm is bound to fail / overflow.
Higham, Nicholas J. (1996). Accuracy and Stability of Numerical Algorithms
Finding a “good” penalty method
The penalty method is a common method for handling complex constraints in optimization problems. This method replaces a constrained optimization problem by a series of 1 or more unconstrained problems. This is achieved by integrating the constraint as an extra cost (penalty function) to the objective function.
However, constructing a penalty function, that is both robust to initial guess and well-conditioned, is indeed a challenge.
Smith, Alice E.; Coit David W. Penalty functions Handbook of Evolutionary Computation, Section C 5.2. Oxford University Press and Institute of Physics Publishing, 1996.
Case Study
Let’s look at a case where we have an objective function F(X) subject to a range constraint. A little bit more formally:
Our goal is to minimize F(X)
Subject to: a < G(X) < b
Where:
- X is the vector of independent variables.
- a, b are constants.
- F: R^n -> R^m
- G: R^n -> R^m
- Assume m=1 (and therefore a,b∈R) for the sake of simplicity.
According to penalty method, we would like to construct
F’(X) such that F’(X) = F(X) + H(G(X)).
So, we only need to find a proper H.
Problem
Find H such that:
- H Makes us pay for violating the constraint (even for small violation), otherwise, lets us off the hook. In other words:
- H(w) should approach 0, if w∈(a, b)
- H(w) should approach infinity, if w∉(a, b)
- H must be smooth (*).
- The initial guess may be inappropriate, namely, out of H feasible region.

- A solution X must satisfy the constraint: a < G(X) < b
*Common optimizers use Trust-Region Quasi-Newton methods and therefore require a smooth objective function (continuous derivatives of 2nd order) to work correctly.
Attempt #1
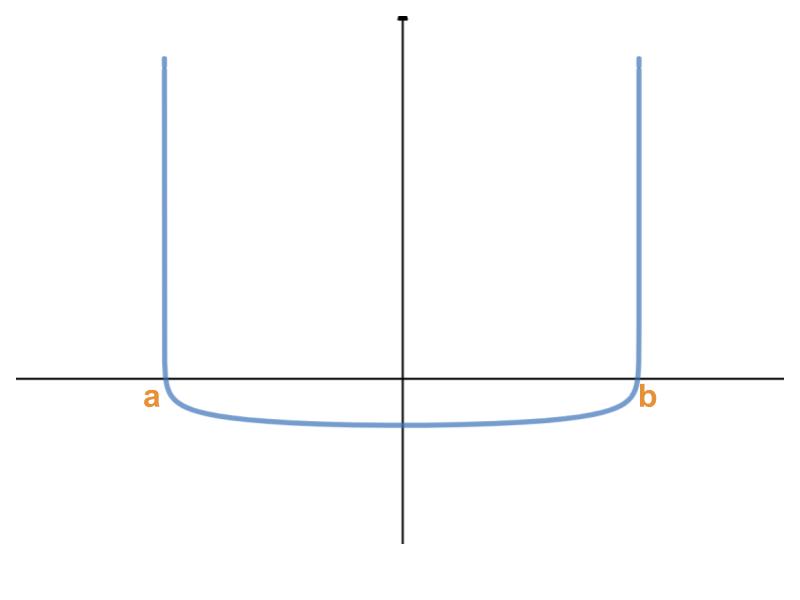
So, which smooth function attains low values inside a certain region and immediately climb to high values, outside of this region?
A common method to be used in such cases is the barrier function. This can be done as follows:
H(w)=-log(b-w) -log(w-a) :
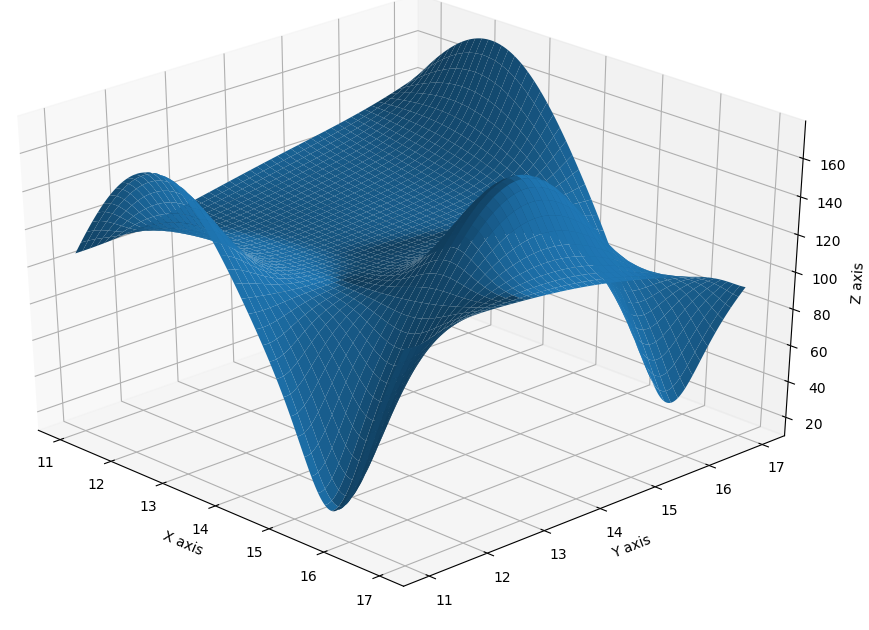
Another alternative is sum of exponents, e.g.:
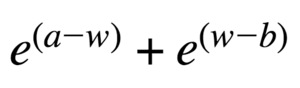
So, why isn’t this a favorable solution?
The value of such a function elevates quickly to magnitudes of millions and billions, therefore:
A. This function is definitely ill-conditioned and due to numerical limitations of floating points, convergence may fail.
B. Evaluating the objective function may trigger an overflow error and crash when stepping outside of the feasible region. (Typically, this can happen when evaluating the gradient or a far initial guess).
Attempt #2
Ok then, sounds like we want a function that has a sharp gradient on one hand, but doesn’t approach infinity on the other hand. Did anyone say sigmoid?
A common sigmoid is implemented by Logistic function:
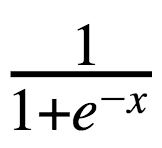
We can construct a sum of sigmoids, such as:
H(w) = Sigmoid(a - w) + Sigmoid(w - b)
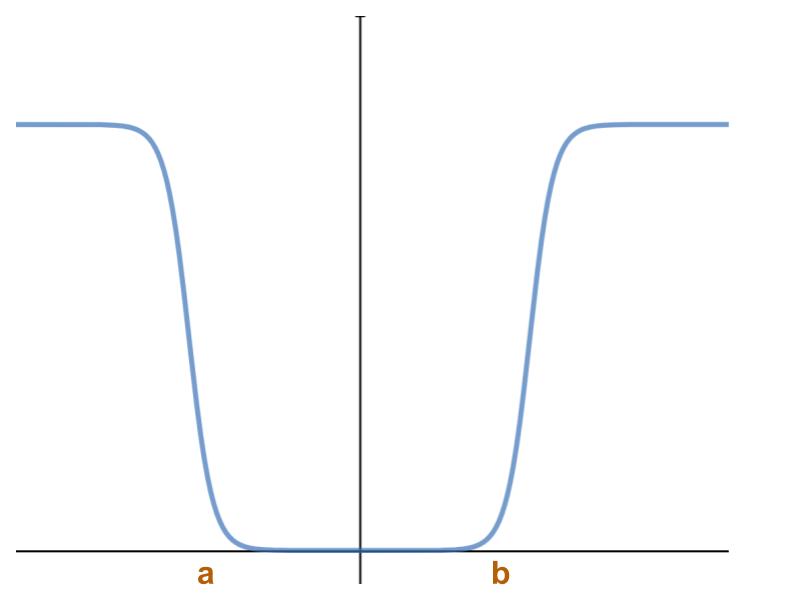
What’s the issue here?
The sigmoid has an infinitesimal gradient when starting far away from the feasible region. Therefore, the optimizer stops on the plateau and doesn’t converge to the minima.
This function only works for an initial guess within the feasible region.
Solution
We’ve learned from the above attempts that on the one hand we’d like something that behaves like a sigmoid within the feasible region, but on the other hand, if we started far-off, we need a substantial gradient to push us into the feasible region.
So, we can already envision something like this:
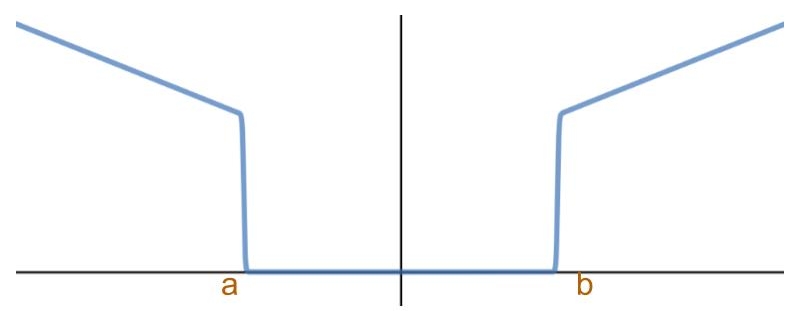
This curve can be constructed in numerous ways, e.g., by using sum of polynomials and other creative solutions.
However, we are after a simple and computationally light solution: Let’s Take advantage of the fact that the sigmoid is dominant only in a certain region and multiply by a linear function that becomes dominant outside of this region:
H(w) = Sigmoid(a - w) * ((a - w) + 1) + Sigmoid(w - b) * ((w - b) + 1)
For the general case, we can parameterize the sharpness of the sigmoid and the factor of the penalty when approaching the boundaries of the feasible region: H(w) = Sigmoid((a - w) * sharpness) * ((a - w) + penalty)
+ Sigmoid((w - b) * sharpness) * ((w - b) + penalty)
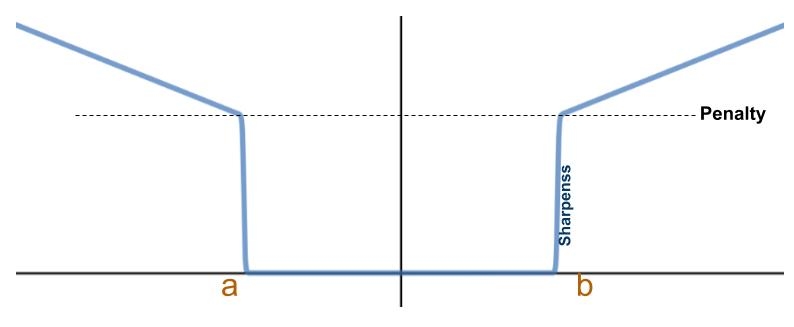
You may notice that this penalty function is not convex; however, this is OK, as most trust-region methods use both 1st and 2nd derivatives (depending on the neighborhood around the point of interest).
Summary
Initial guess often becomes the Achilles heel of nonlinear optimization routines. Therefore, when designing an objective or penalty function, one should consider how the function behaves far from the feasible region and take into account numerical limitations.
I’m sure there are many ways to tackle this issue, including formulating alternative functions, or using alternative methods. From my experience, the “sigmoid x linear” function is a graceful solution; it is simple, smooth, fast, well-posed, and extremely robust.