
Choosing Python as the primary programming language holds many clear advantages, including its wide support for scientific programming and AI libraries.
However, there are some disadvantages to using Python in a real-time environment. This post is the second in a series about choosing a software technology stack for a medical imaging company, and will briefly describe the main issue of performance drawbacks, the reasons for this phenomenon and potential approaches to solving these problems.
GLOBAL INTERPRETER LOCK (GIL)
The GIL allows the execution of only one thread at a time in the OS process. In order to perform parallel programming of CPU intensive tasks, multiprocessing features must be used. However, it is important to note that the creation of new processes, as well as process context-switching, takes time.
Unlike other popular programming languages including C# or JAVA, Python is dynamically typed and an interpreted language. It is slow primarily due to its dynamic nature and versatility.
Both C# and Java are compiled to an “Intermediate Language”, such as IL for Java and CIL for C#, and use JIT (just-in-time) compilation to machine code. The JIT compiler can make the execution faster by knowing the target CPU architecture, and enables optimizations to be made at runtime. A good JIT optimizer will see which parts of the application are being executed often and optimize them.
In addition, the static typing of these languages allows the compiler to make even more optimizations.
However, the dynamic typing of Python makes it hard to optimize, as the interpreter has far less information about the code than if it were a statically typed language.
HOW CAN WE OVERCOME THIS?
The first action in solving a performance problem is to locate the bottleneck. In most use cases, Python’s speed limitations won’t be noticeable. The area that is mostly influenced is the CPU-intensive tasks, for example numeric calculations.
Here are some solutions that can be applied to tackle this problem:
- Multiprocessing to bypass the GIL limitation
- External libraries that are faster and release GIL, allowing multithreading
- Writing your own C++ library
- Numba, which speeds up Python by JIT-compiling to native code
EXTERNAL LIBRARIES
Some external libraries like Numpy and Scipy use efficient C++ implementations that can speed up standard tasks. A problem arises when those libraries can’t offer pre-implemented solutions for specific calculations.
WRITING YOUR OWN C++ LIBRARY
Another option is to write your own C++ library and then wrap it using tools, such as Boost.Python, to create a Python friendly API.
NUMBA
Numba is a JIT compiler for Python that speeds up calculation-focused and computationally heavy Python functions (e.g. loops). It also supports standard libraries like Numpy which, unlike other Python compilers, allow the code to be written in Python without changes. Using Numba only requires adding decorators to your functions while implementing them in regular Python.

The Numba decorator contains a declaration of function parameter types and some arguments for the Numba execution (e.g. cache the function result, use GIL, etc.)
HOW DOES IT WORK?
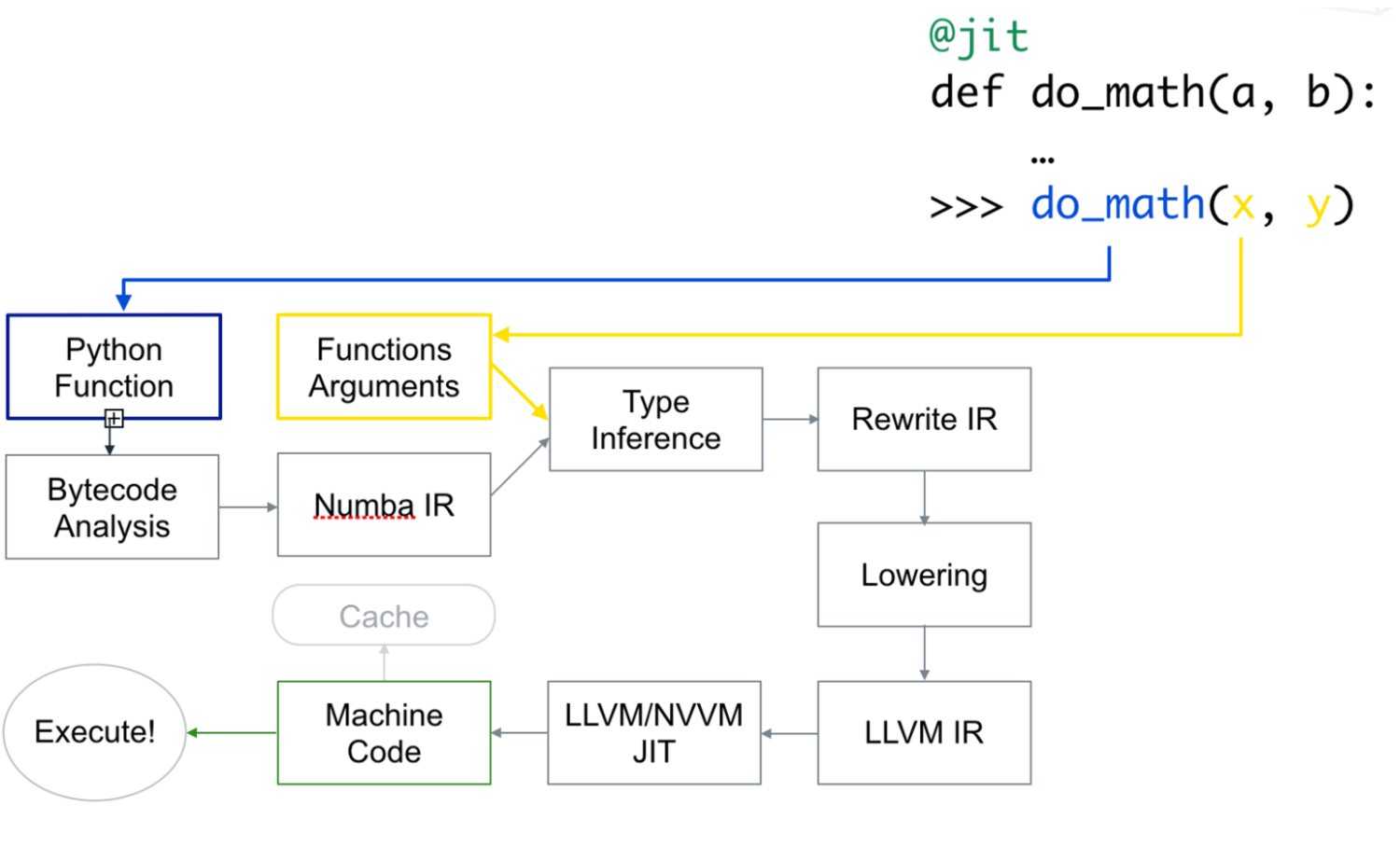
[source]
Numba generates optimized machine code from pure Python code using LLVM compiler infrastructure. The speed of code while using Numba is comparable to that of similar code in C, C++ or Fortran.
First, the Python function is taken, optimized and converted to Numba’s intermediate representation. Then, as a result of type inference, it is converted into LLVM interpretable code. This code is then fed to LLVM’s JIT compiler to give out machine code. The JIT compilation can also be performed offline to improve performance.

FURTHER READING AND REFERENCES
- Why Python is slow - https://hackernoon.com/why-is-python-so-slow-e5074b6fe55b
- Boost.Python - https://www.boost.org/
- Numba - https://towardsdatascience.com/speed-up-your-algorithms-part-2-numba-293e554c5cc1
- Numba tutorial - https://github.com/ContinuumIO/gtc2017-numba/blob/master/1%20-%20Numba%20Basics.ipynb
- LLVM compiler - http://llvm.org/